안녕하세요. 이번시간에는 CPU 캐시에 대해서 알아보도록 하겠습니다.
CPU 캐시에 대해 알아보기 전에 우선 CPU에 대해서 간단하게 살펴볼까요?👀

✔️ CPU 란? (Central Processing Unit)
📖 위키백과에서.
- 컴퓨터 시스템을 통제하고 프로그램의 연산을 실행 · 처리하는 가장 핵심적인 컴퓨터의 제어 장치, 혹은 그 기능을 내장한 칩이다.
- 컴퓨터 안의 중앙 처리 장치(CPU)는 외부에서 정보를 입력받고, 기억하고, 컴퓨터 프로그램의 명령어를 해석하여 연산하고, 외부로 출력하는 역할을 한다.
- 컴퓨터 부품과 정보를 교환하면서 컴퓨터 시스템 전체를 제어하는 장치로, 모든 컴퓨터의 작동과정이 중앙 처리 장치(CPU)의 제어를 받기 때문에 컴퓨터의 두뇌에 해당한다고 할 수 있다.
- 실제의 CPU 칩엔 실행 부분뿐만 아니라 캐시 등의 부가 장치가 통합된 경우가 많다.
그리고 해당 위키백과 글에선 나와 있지 않지만 CPU의 캐시, 레지스터 등은 SRAM을 기반으로 만들어 졌다고 합니다.
👀그럼 왜 CPU는 DRAM이 아닌 SRAM을 사용하였을까? 아래의 표로 두가지를 비교해 보자!
| SRAM (Static Random Access Memory) |
DRAM (Dynamic Random Access Memory) |
|
| 속도 | 빠름 | 비교적 느림, 리프레시를 통한 액세스 지연 발생 가능. |
| 휘발성 | 비휘발성 | 휘발성 |
| 비용 | 비쌈 | 비교적 저렴 |
| 전력 소모 | 한번 저장시에는 더 비싸지만 리프레시가 없기 때문에 비교적 낮음(단 고속 클럭 주파수에선 DRAM과 비슷하거나 더 클 정도로 커질 수 있음.) | 데이터를 유지하기 위해 리프레시를 하여야 하므로 비교적 더 많음 |
| 용도 | CPU 캐시, 레지스터 파일 등 | PC나 스마트폰의 메인메모리 |
| 저장 방식 | 정적 | 동적 |
| 용량 | 적은 메모리 | 대용량 메모리 |
🤔우선 제가 생각하기에 CPU 캐시에 SRAM을 선택한 이유는!
당연히 빠른 속도를 이유로 들 수 있겠지만 레지스터 파일과 같은 데이터는 컴퓨터가 실행 되면 꺼질때까지 사용이 되는데요. 그럼 DRAM을 사용하였다면 컴퓨터를 종료 할 때까지 계속 리프레시를 해야 할 것입니다. 하지만 SRAM을 사용하면 최초 한번 저장시에만 비용이 발생 하게 되고 더 빠른 속도까지 얻을 수 있게 됩니다. 또한 CPU 캐시도 주로 사용 되는 데이터를 저장 하여 빠르게 액세스 하여야 하기 때문에 SRAM을 선택하게 되었을 것 같습니다.
우선은 CPU에 대해서 간단하게 살펴 봤는데요 이제 본격적으로 CPU 캐시에 대해 알아봅시다!
🎛️ CPU 캐시 구조
우선 캐시는 L1, L2, L3의 점차 크기가 커지는 캐시 구조를 가지고 있는데요.
그 이유는 아래의 사진처럼 실생활에서도 자주 발생하는 병목현상을 줄이기 위해서 이러한 구조를 가지게 되었습니다.

📫 우선 메모리는 캐시메모리에 비해서 엄청나게 큰데요. (아래는 제 PC 기준으로 작성하였습니다.)


CPU가 L1(1.4MB), L2(14MB), L3(30MB) 와 같은 계층화 구조를 가지게 된 이유는 상대적으로 크기가 매우 큰 보조기억장치(1TB)와, 주기억장치(32GB) 의 데이터들을 CPU가 사용 할 수 있게 가져올 때 병목 현상을 최대한 줄이며 가져오기 위함입니다.
CPU가 메인메모리에 올라와 있는 메모리(주기억장치)를 사용하기 위해선 현재 사용할 데이터들만 읽어와 공유 캐시 메모리 L3에 저장을 하게 되고, L1, L2 캐시에서 해당 L3 캐시를 참조하여 사용하게 됩니다. (이런식으로 데이터의 위치를 결정하는 것을 캐시 사상(mapping) 이라고 합니다.)
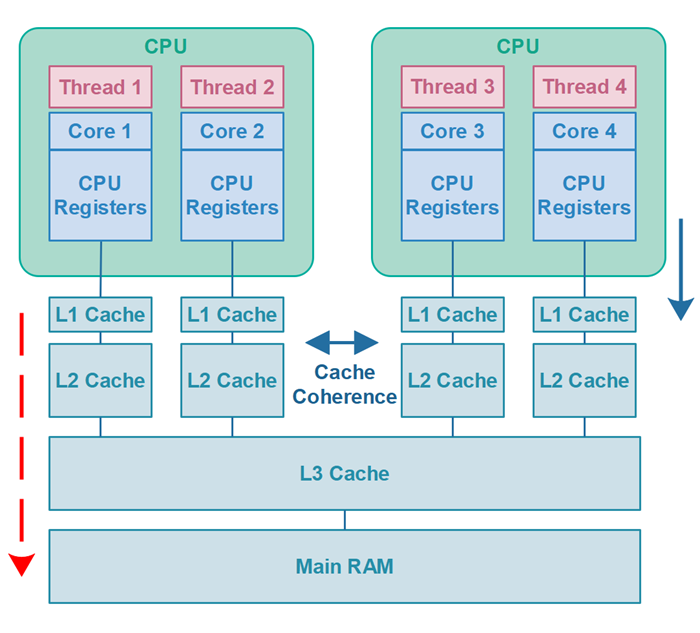
L1 캐시
- L1 캐시는 CPU 코어 내에서 코어와 가장 가까이에 위치합니다.
- L1 명령어캐시와 데이터캐시로 나뉜다.
- 레지스터 파일 다음으로 CPU에서 매우 빠른 읽기 및 쓰기 작업을 지원합니다.
- 자주 사용하는 데이터나 명령을 저장하고 있습니다.
L2 캐시
- CPU 외부에 가까이 존재 할 수도 있습니다.
- L2 캐시는 여러 CPU 코어가 공유하는 경우도 있습니다.
- L1캐시에서 캐시 미스가 났을 경우 사용됩니다.
- L1보다 상대적으로 느리지만 크기가 더 크고 메인메모리보다는 여전히 훨씬 빠릅니다.
L3 캐시
- L1, L2 보다는 더 느리지만 여전히 메인메모리보다 훨씬 빠릅니다.
- 멀티코어 환경에서도 각각의 코어는 L3 메모리를 공유하고 있습니다.
- CPU가 찾는 데이터가 L3에도 없을 경우 CPU는 주기억장치에 직접 액세스 하여 데이터를 가져온 후 L3캐시에 로드합니다.
🌟그럼 해당 CPU 캐시 들에 대해 용어와 함께 정리를 해볼까요?
- 🎯 캐시 히트
- CPU가 필요로 하는 정보가 캐시에 존재 할 때를 말합니다.
- 캐시 히트는 메모리 액세스의 성능을 높이는 핵심적인 이벤트입니다.
- L1 -> L2 -> L3으로 순차적으로 찾습니다.
- 💩 캐시 미스
- CPU가 찾는 정보가 캐시에 들어 있지 않을 때를 말합니다.
- 이 경우 CPU는 원하는 데이터를 메인 메모리나 다른 저장 위치에서 찾아와야합니다.
- 🌧️ 미스 패널티
- 캐시 미스 상황 발생 시 CPU가 직접 원하는 데이터를 메인메모리나 다른 저장 장치에서 찾아와야 하며 이는 액세스 지연과 대기 시간을 포함합니다.
- 캐시 미스가 많이 발생하여 해당 비용이 많이 발생 할 시 성능 저하의 원인이 됩니다.
- 💽 히트 레이턴시
- 캐시 히트가 발생했을 때에도 검색 하는 비용이 발생하는데 해당 시간을 말합니다.
- 이는 캐시 히트 상황에서도 발생하는 액세스 지연 시간을 말합니다.
- 🗃️ 캐시의 지역성
- ⏱️시간적 지역성은 지금 어떤 데이터를 사용했다면 가까운 미래에 다시 사용할 확률이 높다는 것을 말합니다.
- 📉공간적 지역성은 어떤 데이터가 사용된다면 그와 인접한 데이터에 다시 접근 할 확률이 높다는 것을 말합니다.
아래의 코드는 함께 공부를 하고 있는 지인분께서 지역성에 관하여 공부하실 때 주셨던 코드인데요.
public class Main {
private static final int SIZE = 10_000;
private static final int[][] array1 = new int[SIZE][SIZE];
private static final int[][] array2 = new int[SIZE][SIZE];
public static void main(String[] args) {
long start, end;
// Cache Thrashing X
start = System.nanoTime();
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
array1[i][j]++; // 로우 기준 접근
array2[i][j]++;
}
}
end = System.nanoTime();
System.out.println("No Cache Thrashing: " + (end - start) / 1_000_000 + " ms");
// Cache Thrashing O
start = System.nanoTime();
for (int i = 0; i < SIZE; i++) {
for (int j = 0; j < SIZE; j++) {
array1[j][i]++; // 컬럼 기준 접근
array2[j][i]++;
}
}
end = System.nanoTime();
System.out.println("Cache Thrashing: " + (end - start) / 1_000_000 + " ms");
}
}(좋은 정보 공유해주신 Jun님 감사합니다. 🥹)
해당 코드는 자바에서 배열에 접근 할 때 컬럼을 기준으로 접근 할 때와 로우를 기준으로 접근 할 때의 속도의 차이를 비교하기 위한 코드입니다.
과연 여러분들이 생각하시기에는 어떤 결과가 나오실 것 같나요?

결과는 컬럼보다 로우를 기준으로 접근 할 때 제 PC를 기준으로 약 40배 정도의 차이가 발생합니다! (PC 성능 마다 차이가 있음.) 이는 위에서 설명 드린 캐시의 지역성 중 공간적 지역성에 해당합니다! 배열은 상대적으로 가까운 메모리 위치에 있는 데이터로써 해당 데이터의 근처에 있는 데이터를 다시 접근할 가능성이 높아 캐시 라인 크기 내에서 같이 가져오므로 캐시히트 상황이 많아져 성능이 빨라지게 되고, 반대로 10,000 * 10,000 의 2차원 배열을 컬럼을 기준으로 가져올 경우에는 거의 대부분 캐시미스가 발생 하기 때문에 확연히 성능 차이가 나게 되는 것입니다.
💭 캐시 사상 (Cache Memory Mapping Process)
캐시 사상에는 가장 대표적인 3가지의 사상에 대해 설명드리겠습니다.
- 직접 사상 (Direct Mapping)
- 가장 간단한 캐시 사상 방법 중 하나입니다.
- 주 메모리 주소를 캐시 메모리 주소로 변환 하는데 사용되는 해시 함수를 사용하여 각 주소를 고정된 위치의 캐시 블록에 매핑합니다.
- 특정 메인메모리 주소는 항상 특정 캐시 블록에 저장됩니다.
- 이 방법은 충돌 가능성이 있으며 동시에 여러 주소가 동일한 캐시 위치로 매핑 될 수 있습니다.
- 연관 사상 (Associative Mapping)
- 연관 사상 방식은 메인메모리 주소를 캐시 메모리의 여러 위치 중 어느 위치에든 저장 할 수 있는 방법입니다.
- 해시 함수를 사용하지 않고 데이터를 찾을 때 모든 캐시 위치를 동시에 검색합니다.
- 충돌 문제는 없지만 더 복잡하고 비싼 하드웨어가 필요합니다.
- 일반적으로 N-Way 연관 사상이라고 표현되며 N은 한 번에 여러 블록을 저장할 수 있는 캐시의 등급을 나타냅니다.
- 직접 연관 사상 (Set Associative Mapping)
- 직접 연관 사상은 직접 사상과 연관 사상의 중간 방식으로, 캐시를 여러 세트로 나눕니다.
- 각 세트에는 일정 수의 캐시 라인이 포함되며, 메인메모리 주소가 특정 세트에 매핑됩니다.
- 한 세트 내에서는 연관 사상 방식을 사용하므로 동일한 세트 내에서는 충돌 문제가 발생하지 않지만 다른 세트 간에는 충돌이 발생할 수 있습니다.
🍒 캐시 교체 알고리즘
LRU (Least Recently Used)
- 가장 오랫동안 참조되지 않은 페이지를 교체하는 방식입니다.
- 과거의 참조 기록을 기반으로 가장 오랫동안 참조 되지않은 데이터가 가장 사용 될 확률이 적다고 판단 하는 것입니다.
LFU (Least Frequently Used)
- 사용 횟수가 가장 적은 페이지를 교체 하는 방식입니다.
- 과거의 참조 기록을 기반으로 가장 적게 참조 된 페이지가 가장 사용 될 확률이 적다고 판단 하는 것입니다.
FIFO (First-In-First-Out)
- 가장 먼저 들어온 페이지를 교체 하는 방식입니다.
Optimal
- 향후 가장 참조되지 않을 페이지를 교체 하는 방식입니다.
- 최적 근접 알고리즘이라고 불립니다.
- 미래의 사용 될 페이지를 미리 예측하고 교체 하는 방식으로 실제로 구현은 불가능 하지만 최적의 성능을 비교할 때 사용 되는 방식입니다.
SCR(Second Chance Replacement)
- 가장 오랫동안 주기억장치에 있던 페이지 중 자주 사용되는 페이지의 교체를 방지하는 것입니다.
- 참조 비트를 두어 1이면 0으로 바꾸고, 0이면 교체 대상으로 선택합니다.
- 즉 FIFO 에서 한번더 기회를 주는 방식입니다.
🌵 자 그렇다면 이번엔 다음의 코드를 실행 시키면 어떻게 될까요?
public class CPUCacheTest {
static Boolean flag = true;
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() ->{
long count = 0;
while (flag) {
count++;
if (count > 1000000000000000000L) {
break;
}
}
System.out.println("thread1 end!! count : "+ count);
});
Thread thread2 = new Thread(() ->{
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("thread2 flag = " + flag);
}
flag = false;
System.out.println("thread2 flag = " + flag);
});
thread1.start();
thread2.start();
}
}1000000000000000000L = 10경의 크기인데요. 아무리 성능이 좋은 컴퓨터라 할 지라도 해당 로직에서 약 0.5초만에 절때 해당 크기에 도달할 수 없습니다❌.
그럼 이 문제의 답변 중 정답은 무엇일까요?
- 1000000000000000001까지 도달한 후에 종료 된다.
- 1000000000000000001에 도달하기 전에 종료 된다.
결과는 아래와 같이 나옵니다.

만약 여기 flag 변수에 volatile 키워드를 붙이면 어떤 결과가 나올까요?
public class CPUCacheTest {
...
volatile static Boolean flag = true;
...
}
🌈 짠! 저희가 원하던 시점에 정상적으로 종료가 된 것을 확인 할 수 있습니다.
이러한 사항이 발생하게 된 이유가 뭘까요?🤔
바로 캐시 일관성이 지켜지지 않은 문제입니다. 위 예제에서는 volatile 키워드를 사용하여 동기화 되지 않아 발생한 캐시 일관성 문제를 해결 하였습니다. (volatile은 CPU캐시 문제 해결하기 위한 방법 중 한가지.)
- 쓰레드 1의 L1 캐시메모리가 A라고 하고 쓰레드 2의 L1 캐시메모리가 B라고 한다면.
- CPU의 서로 다른 쓰레드는 L3공유 메모리에 있는 flag의 데이터를 읽어와서 각 A, B(L1)에 담아두게 됩니다.
- 서로 다른 L1에 flag 값을 각각 저장이 되어있습니다.
- 쓰레드 2에서 flag 값을 변경하면 B캐쉬와 L3에 flag 값은 서로 동기화 되며 변경이 이루어집니다.
- 하지만 여전히 쓰레드1는 flag 데이터 탐색 시 L1부터 순차적으로 탐색하기 때문에 동기화 되지 않은 flag 데이터를 가지고 있는 A에서 캐시히트가 됩니다.
- 결과적으로 쓰레드1은 L3의 동기화 된 캐시를 읽어오지 않고 A(L1)의 캐시를 계속 사용하게 되어 동기화 되지 않아 쓰레드1은 중간에 멈추지 않고 끝까지 동작하게 됩니다.
🌠 직접 구현 하다가 알게 된 또 다른 사실!
...
static Boolean flag = true;
...
Thread thread1 = new Thread(() ->{
long count = 0;
while (flag) {
count++;
// 이부분에 삽입 시작!!!
System.out.println("아무거나 프린팅")
// 이부분에 삽입 끝!!!
}
System.out.println("thread1 end!! count : "+ count);
});
...만약 위의 로직에서 volatile 키워드 없이 주석한 부분에 println() 를 추가 하면 여러분들은 어떻게 동작이 될 것 같나요?🤔
volatile을 붙인 것과 별반 다름 없이(실제로는 살짝 차이가 발생 아래서 설명.) 로직이 중간에 정상적으로 멈추게 됩니다.
이미 아시는 분들도 많으시겠지만 저는 처음 보자마자 왜 되는거지!! 하고 놀랐었는데요🫢.
이에 궁금증에서 멈추지 않고 같이 공부 하시는 분들에게 물어보고 토론하며 찾아보는 등 그 이유에 대해 더 깊게 학습해보았습니다.!
그결과..!! 해당 사건의 정답에는 println의 내부 로직에는 synchronized 블럭 즉, 동기화가 붙어있습니다.
public class PrintStream extends FilterOutputStream implements Appendable, Closeable {
...
private void write(String s) {
try {
synchronized (this) {
ensureOpen();
textOut.write(s);
textOut.flushBuffer();
charOut.flushBuffer();
if (autoFlush && (s.indexOf('\n') >= 0))
out.flush();
}
}
catch (InterruptedIOException x) {
Thread.currentThread().interrupt();
}
catch (IOException x) {
trouble = true;
}
}
...
}과연 동기화를 통해서 어떻게 CPU의 캐시 정보를 새로 고치게 되는걸까요?👀
🍀 자바에서 멀티쓰레드 환경에서 synchronized 블럭을 통해 동기화를 하게 되면 실행되고 있는 쓰레드는 락을 획득하기 위해 경쟁을 하게 됩니다.
1. 이 때 락을 획득하지 못한 경우 쓰레드가 대기상태로 들어가게 됩니다.
2. 이를 통해 CPU에서는 대기 상태로 들어간 쓰레드를 다른 쓰레드에게 할당하게 되고 이는 컨텍스트 스위칭이 발생하게 됩니다.
3. 그 결과 대기 중이 였던 쓰레드가 락을 획득하여 다시 실행 됩니다.
4. 해당 쓰레드가 기존에 실행되던 CPU 코어가 아닌 다른 CPU코어의 쓰레드로 실행하게 됩니다.
5. 이 경우 캐시 미스가 발생하게 되어 새로 캐시 정보를 L3에서 받아오게 되며 일시적으로 성능저하와 함께 해당 flag 값을 새로 갱신하게 되는 것입니다.
✅ 내 생각 정리
사실 예전에 실무에서 volatile을 보고 이게 뭐지?👀 하고 학습하여 어렴풋이 알고 있던 내용이였지만, 다시 공부하다보니 synchronized로도 컨텍스트 스위칭을 통해 CPU의 캐시를 다시 가져오게 할 수 있는 것은 처음 알게 되어 너무 새롭고 재미있었습니다.☺️ 하지만 synchronized를 통한 캐시를 다시 받아오는 방법은 동일한 CPU의 쓰레드에서 다시 진행하게 될 경우 캐시 히트되어 새로 고침이 되지 않을 가능성도 있어 완벽하게 volatile을 대체하여 사용할 수는 없을 것 같습니다.👍
'CS' 카테고리의 다른 글
| Encoding, Decoding 그리고 Encrypt, Decrypt 제대로 알아보자! (2) | 2024.07.29 |
|---|
